平方损失
平方损失 Square Error ,作为机器学习中最为经典,也是最为朴素的损失算法,值得进一步进行探讨。
本篇文章对背后的数学原理、最优化算法进行探讨。
概率数学原理
简单理解(图像)

数据如下表
| x0 |
y |
| 1 |
1 |
| 2 |
3 |
| 3 |
2 |
| 4 |
6 |
| 5.06 |
7.23 |
| 6 |
7 |
上图中的绿色点都是对应数据样本在二维笛卡尔坐标系中的描点。
现在需要考虑的是如何衡量数据样本与预测值的偏差。
在几何中可以通过距离表示,那么我们只需要计算距离即可。
由平面直角坐标系距离公式可知
L2=(x1−x2)2+(y1−y2)2
代入数据点(x0,y),预测点(x0,h(x0))可得
L2=(x0−x0)2+(y−h(x0))2=(y−h(x0))2
即可导出均方误差公式为
E(xi)=2m1i=0∑m(yi−θxi)2
深入理解(概率统计)
机器学习中的很多算法并不只是表面的直观理解,其实内部还有很多的数学原理。
这部分通过极大似然法来对为什么是平方来进行理解。
对于真实世界的预测,我们可以写为
y=θx+ε
我们令 ε 为真实世界中被忽视或无法获取的特征的和,可以变形为
ε=y−θx
在生活经验中,ε 非常接近钟形分布,即高斯正态分布,于是
ε∽N(μ,σ2)
展开得
f(ε)=2πσ1⋅e−2σ2(y−θx−μ)2
我们计算出出现 f(ε) 的概率,记为 P(ε)
P(ε)=D∏f(ε)=D∏2πσ1⋅e−2σ2(y−θx−μ)2
我们选择对它取对数操作,对数是增函数
L(ε)=lnP(ε)=D∑ln2πσ1+D∑lne−2σ2(y−θx−μ)2=D∑ln2πσ1+D∑−2σ2(y−θx−μ)2
因为第一项是一个常数,所以我们要让 P(ε) 最大,于是要让 L(ε) 最大,于是要让下式最小
2σ2(y−θx−μ)2
只需要不断优化 θ 使得 (y−θx)2 最小,即
minimize (y−θx)2
这意味着接下来我们需要通过不同方法进行上述操作
梯度下降
定义
梯度下降法 (gradient descent) 是一个最优化算法,常用于机器学习和人工智能当中递归逼近最小偏差模型。
在已知表达式的情况下可以代替二分三分,且效率较高。
在发展过程中衍生出了随机梯度下降算法和批量梯度下降算法,本文介绍批量梯度下降算法。
数学原理
推导过程
以线性回归为例,不妨令 xi 为第 i 组输入数据,h(xi) 为预测结果
h(x(i))=θx(i)
(损失函数)
此处使用均方误差(又称最小二乘法)
令误差函数为E(xi,yi)得
E(xi,yi)=2m1i=0∑m(yi−h(xi))2=2m1i=0∑m(yi−θxi)2
由于我们的目的是通过数据拟合出函数,换句话说是调整 θ 的值
所以我们更换主元为 θ ,并构造损失函数 J(θ) 得
J(θ)=2m1i=0∑m(yi−θxi)2
(批量梯度下降)
并对上式求关于 θ 的偏导得
J′(θ)=∂θj∂J(θ)=m1i=0∑m(θxi−yi)xji
我们需要通过上式确定迭代的方向,并不断迭代直到收敛
于是得到递推式为
θj=θj−J′(θj)α
上式中的α为学习率,可以控制没移动一步的快慢。若α设置过大,则可能出现偏差越迭代越大的情况;若α设置过小,则训练耗时越大。需要正确选择学习率的大小。
迭代的过程如下图所示.

过程详解
可以用盲人爬山来简单形容。
盲人爬山闭着眼,要用脚试一下是往下的,那就走,一直这样操作,最终下山。当然这也就暴露出了其问题,无法一次性找到全局最优解。
可以用图像来简单说明。
这是损失函数(两个 θ )的大致图像,我们需要找到最低点时的 θj 的值。
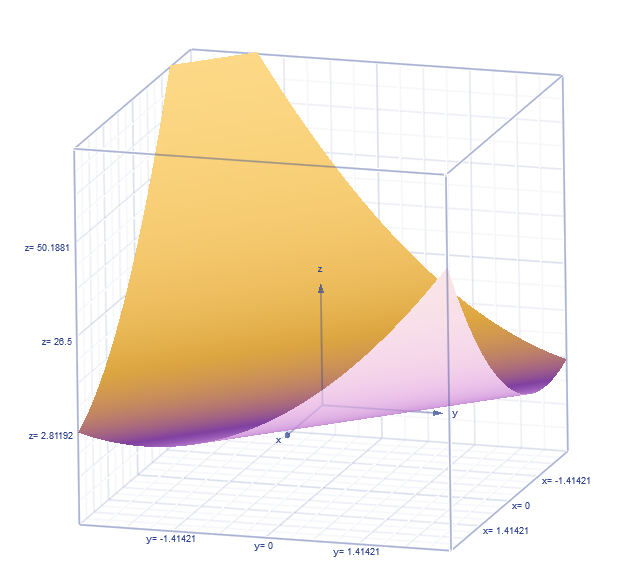
直接观察三维图像可能比较抽象,我们不妨先看二维,再拓展到三维。
在图中横截一条线如下图

注:曲线为函数图像;直线为对应点的切线(即 J′(θ1) 项的值)
y=(x−3)2+1
y1′=6x−26
y2′=3.6x−13.04
y3′=2x−6
y4′=x−2.25
数据如下表
| x |
y |
J′(θ) |
| 6 |
10 |
6 |
| 4.8 |
4.24 |
3.6 |
| 4 |
2 |
2 |
| 3.5 |
1.25 |
1 |
| 3.2 |
1.04 |
0.4 |
| 3.1 |
1.01 |
0.2 |
| 3.05 |
1.0025 |
0.1 |
| 3 |
1 |
0 |
当 k>0 时,说明 θ1 位于 θ 的右侧,即要减去一个值
当 k<0 时,说明 θ1 位于 θ 的左侧,即要加上一个值
于是 θ1=θ1−J′(θ1)α
实际上 n 元线性回归(逻辑回归)是 n+1 维的图像,我们可以类比理解。
实现
线性回归
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
#include <iostream>
#include <algorithm>
#include <ctime>
using namespace std;
int n,m;
double pre(double a[],double b[]){
double h=0;
for(int i=1;i<=m;i++){
h=h+a[i]*b[i];
}
return h;
}
int main(){
double x[105][15],y[105],w[105],k=0.001,lam=0;
w[0]=0;
cin>>n>>m;
for(int i=1;i<=n;i++){
x[i][0]=1;
for(int j=1;j<=m;j++)
cin>>x[i][j];
cin>>y[i];
}
int iteration=200,q=0;
double regular=lam/((double)n);
while(iteration--){
for(int p=0;p<=m;p++){
double s=0;
for(int i=0;i<=n;i++){
double predict=pre(x[i],w);
double loss=predict-y[i];
s=s+loss*x[i][p];
}
s=s/n;
w[p]=w[p]-s*k-regular*w[p];
}
if(iteration%1==0){
printf("Try %d:\t",++q);
for(int i=0;i<=m;i++) printf("%.3lf ",w[i]);
printf("\n");
}
}
printf("Result: ");
for(int i=0;i<=m;i++) printf("%.3lf ",w[i]);
printf("\n");
double xl[105];
for(int i=1;i<=m;i++) cin>>xl[i];
printf("%.0lf",pre(w,xl));
return 0;
}
|
逻辑回归
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
#include <iostream>
#include <algorithm>
#include <cmath>
using namespace std;
int n,m;
double w[105];
double z(double xx[]){
double h=0;
for(int i=1;i<=m;i++){
h=h+xx[i]*w[i];
}
return h;
}
double f(double zz){
double tm1=exp(-zz);
double tm2=1+tm1;
double fin=1/tm2;
return fin;
}
int main() {
double x[20][105],y[200],aph=0.0001,lam=0;
cin>>m>>n;
for(int i=1;i<=m;i++){
x[i][0]=1;
for(int j=1;j<=n;j++) cin>>x[i][j];
cin>>y[i];
}
int iter=2000;
double regular=lam/((double)m);
while(iter--){
for(int j=0;j<=n;j++){
double loss=0.00;
for(int i=0;i<=m;i++)
loss=loss+(f(z(x[i]))-y[i])*x[i][j];
loss=loss/m;
w[j]=w[j]-loss*aph-regular*w[j];
}
if(iter%100==0){
for(int k=0;k<=n;k++)
printf("%.3lf ",w[k]);
printf("\n");
}
}
printf("train over\n");
for(int i=0;i<=n;i++) printf("%.3lf ",w[i]);
printf("\n");
return 0;
}
|
正规方程
定义
正规方程 (Normal Equation) ,是一个快速计算局部极值的方法。在数据量不大( n<1000 )左右时优于梯度下降算法(取决于个人机器性能限制)。
在知道表达式的情况下可以代替二分查找或三分查找。现在多用于s人工智能(机器学习)领域。
结合曾经的竞赛题目,这个技巧不太可能考到,但学习它还是需要的。
数学原理
不妨令
X=⎣⎢⎢⎡111x11x12x1mx21x22...x2m.........xn1xn1xnm⎦⎥⎥⎤
y=⎣⎢⎢⎡y1y2…ym⎦⎥⎥⎤,θ=⎣⎢⎢⎡θ1θ2…θn⎦⎥⎥⎤
则预测函数为
y=Xθ
J(θ)=(y−Xθ)2
∂θ∂J(θ)=2(y−Xθ)XT
令上式为 0 即得最小值
2(y−Xθ)XTyXT−XθXTXTθX(XTX)−1XTXθIθθ=0=0=yXT=yXT(XTX)−1=yXT(XTX)−1=(XTX)−1XTy
实现
C++ 可以使用矩阵计算库 Eigen 或手写矩阵计算
Python 可以使用 Numpy 库或手写
此处使用 C++ 中的 Eigen 库实现
C++
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
#include <iostream>
#include "eigen/Eigen/Eigen"
using namespace std;
using namespace Eigen;
Matrix<double,Dynamic,Dynamic> X;
Matrix<double,Dynamic,1> w;
Matrix<double,Dynamic,1> y;
int main() {
int m,d;
cin>>m>>d;
X.resize(m,d+1);
w.resize(d+1,1);
y.resize(m,1);
X.fill(1);
for(int i=0;i<m;i++){
printf("\nX=\n");
for(int j=1;j<=d;j++){
int q;
cin>>q;
X(i,j)=q;
}
printf("y=");
int q;
cin>>q;
y(i,0)=q;
}
w=(X*X.transpose()).inverse()*X.transpose()*y;
cout<<w;
return 0;
}
|